页次: 1
#1 2022-08-18 02:50:40
- hongyan30
- 会员
- 注册时间: 2022-08-18
- 帖子: 8
鸿雁输入法linux版和windows版 首个突破千万词条的中文输入法
鸿雁拼音和鸿雁五笔发布后,目前下载量到达400人次。
为了提高五笔输入、拼音输入的准确性,让整句输入更为智能。现在把词条的数量从230万升级到1050万。 鸿雁拼音采用220亿字典型语料库分析得出的2-4个字的词语频率数据用于词语候选列表。220亿字的语料库分割为114个区块,区块投票分析出来的有效词语有1000多万条。 目前使用230万的数据,原因window下小狼毫能处理数据量上限低于400万,只好把数据精简。具体原因可能是32位的程序能够申请的内存空间不够,或者可能是调用windows平台Visual C++相关的运行库的相关函数可以支持的内存申请空间有限。
鸿雁拼音和鸿雁五笔目前,使用的是rime系列输入法框架。所以,鸿雁输入法可以顺利移植到Linux平台。
在linux平台,rime输入法有3个适配软件包:ibus-rime、fcitx-rime、fcitx5-rime。
在linux平台,词条数有230万条,ibus-rime生成词库索引过程中,需要6-8GB的内存。词条数有1000万条,需要 10-11GB的内存。
在我的印象里,linux是极客鼓捣的平台,绝大部分人还是使用windows平台。以系统中文输入法框架为例,linux环境就没有相对稳定的软件套件。 一开始是SCIM,后来是有fcitx、iBus、fcitx5。
开源化的软件有一个与生俱来的缺点,就是兴趣驱动,绝大部分获得的报酬很少。 商业化的软件,比如如windows,微软公司高薪聘请专家使用工作时间,多个人组成的团队协同开发软件。不能说微软的产品碾压同类一切产品,至少碾压大部分产品。 绝大部分人选择日常工作生活使用的操作系统,还是选择windows平台。
在一些专业的领域,微软的产品是没有竞争力的。比如,微软的文件管理软件,在复杂的文件操作功能上无法与Total Commander竞争。简单的举例,就搜索文件文件名的功能,也不知道微软是这么优化分词的,经常会漏掉不少结果,而Total Commander搜索结果比较严谨,从来没有出错过。
有人提到,你手里有这么好的词频资源,开个github,争取成为ubuntu官方默认的输入法。 看到这样的提议,想想还有点小激动呢!不用多久,我就会升职加薪,当上总经理,出任CEO,迎娶白富美,走向人生巅峰!
回到现实。 目前鸿雁拼音和鸿雁五笔,只能算一个输入法词库和配置方案。 就算我依葫芦画瓢搞出来一个ibus-hongyanpinyin、ibus-hongyanwubi,就算是天才,起码需要一个星期以上吧。 ibus从2008年开始发起的,fcitx从2002年开始开源。从头开始做一个输入法成本很高,就算仅仅是在现有的输入法框架上做一个软件包,也需要花费不少时间。 230万的词条生成词库索引需要8GB的内存,词条数有1000万条生成词库索引需要11GB的内存,这对于一般的linux发行版可能是不可承受的,因为系统需要兼容那些内存比较小的机器。 个人觉得一个操作系统仅仅需要做一个样板性的、示例性质的拼音输入法就可以了。
既然都会使用linux系统环境了,使用shell环境、源代码安装了。那如果想把鸿雁拼音、鸿雁五笔方案迁移到了linux平台,应该是有办法的。
所以只在文后提供linux安装的命令记录,不提供现成的软件打包,供有需要的极客折腾参考。
如果想在windows平台支持千万级别的超大词库,行不行?
当然可以。可以实施的方案有: 1.修改rime winows版的源代码,采用全新的算法,让windows平台的小狼毫输入法可以支持千万级别的超大词库索引生成。这个代价较高。就算熟知源代码的作者,按照一般情况下估计,最起码要几天才能搞定。 2.在linux生成索引,拿来windows平台。
尝试了第二种方案,居然可行。
使用偷梁换柱大法,做出了一个词库增强包,让windows平台的鸿雁拼音和鸿雁五笔也能支持千万级别的超大词库。
“鸿雁拼音和鸿雁五笔v2.0_1050万词语增强包.exe”软件截图

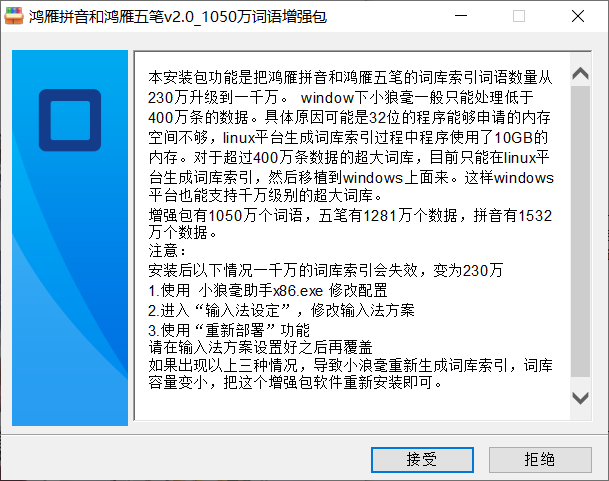
目前,中文输入法,没有听说过有千万词条级别的。也许有,不过很低调,商业输入法云服务端可能使用的数据远超千万。黑马校对的数据也可能超过千万。 具体细节不得而知,只能猜测,这些是商业机密。
商业输入法使用云端使用用户的词语改进热门词汇,这样有利也有弊。弊端是有大量用户在正确的拼音下打出的错误的词语也被收集,这样的词语没有被人工甄别,如果普通用户继续使用云端服务推荐的这些错误的词语,会进入一个死循环。数以亿计的用户,庞大的数据量,人工校核,恐怕人力跟不上。只有人,在参考多方资料才能作出正确的选择,机器算法再强也做不到这一点。目前的人工智能还不能理解人类语言。查字典,查典故,查标准,与现实世界语言环境核查,这些是机器干不了的活,最多只能辅助。
鸿雁输入法打着千万级别词条的噱头,也算是一个吸引用户的方法。 鸿雁输入法是开源的,免费的,离线的,不会收集用户的隐私。 如今加上一个千万级别的词库,会不会让更多的人心动呢?
词库从230万升级到1050万,看看鸿雁输入法有没有变得更懂中文,上图
前面一张图是230万词库的候选词语列表,后面一张图是升级到1050万词库后同样的拼音输入下候选词列表。
[align=center][table=98%][tr][td]升级前[/td][td]升级后[/td][/tr]
[tr][td]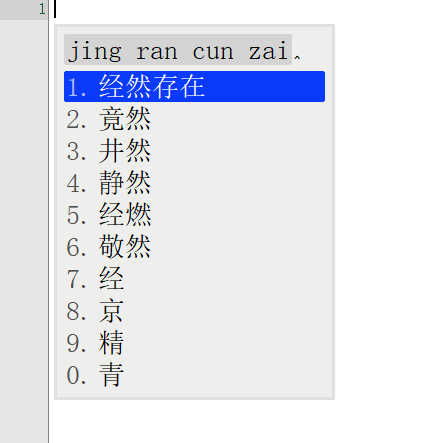 [/td][td]
[/td][td]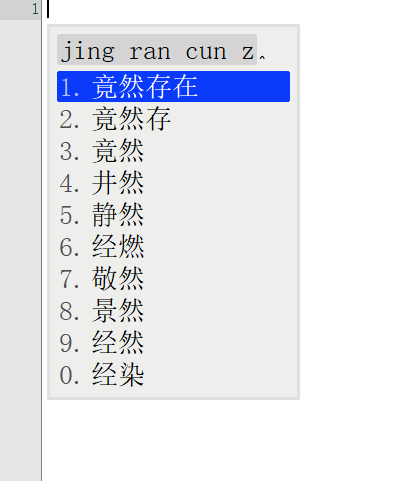 [/td][/tr]
[/td][/tr]
[tr][td]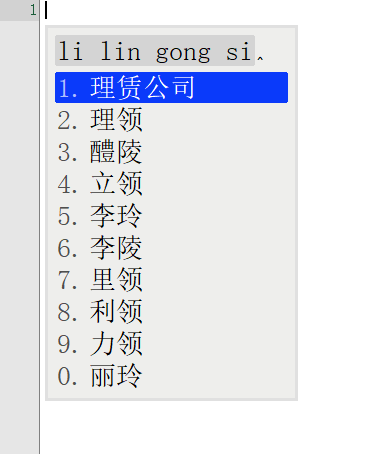 [/td][td]
[/td][td]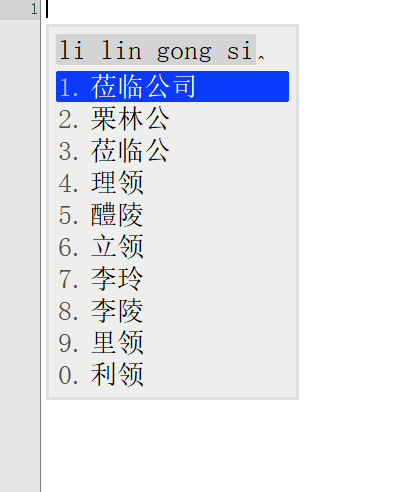 [/td][/tr]
[/td][/tr]
[tr][td] [/td][td]
[/td][td]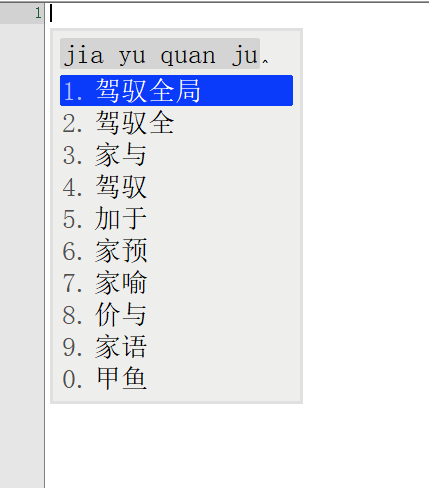 [/td][/tr]
[/td][/tr]
[tr][td]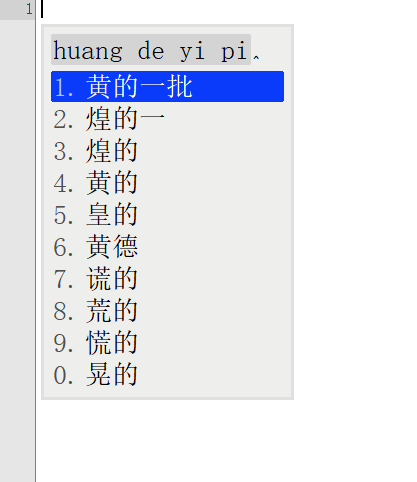 [/td][td]
[/td][td]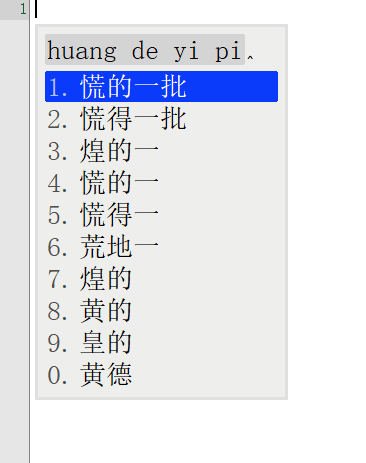 [/td][/tr]
[/td][/tr]
[tr][td]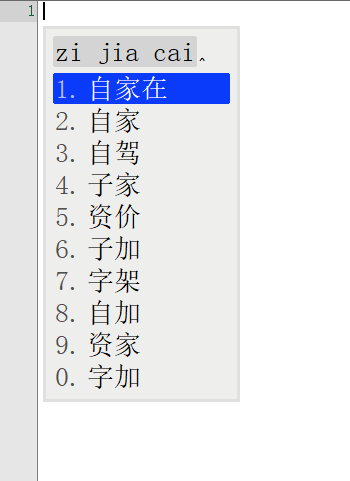 [/td][td]
[/td][td]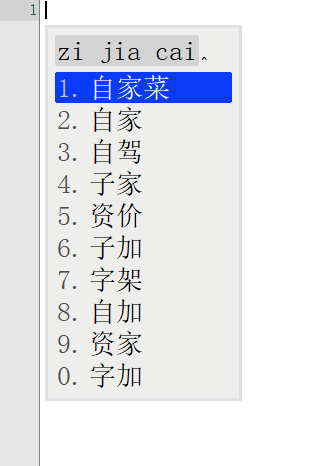 [/td][/tr]
[/td][/tr]
[tr][td]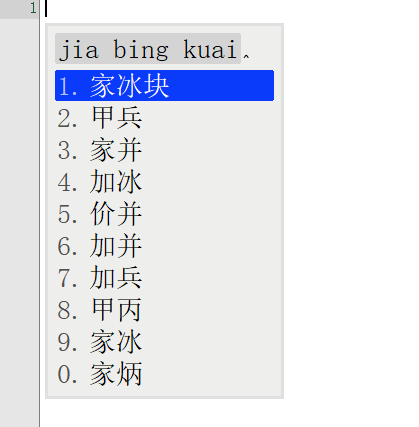 [/td][td]
[/td][td]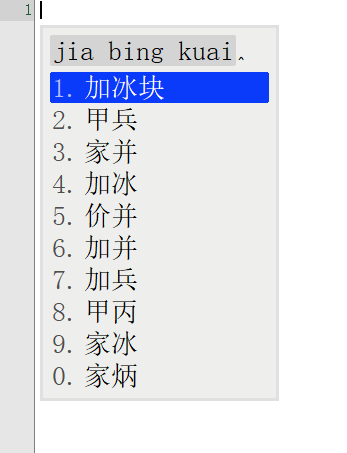 [/td][/tr]
[/td][/tr]
[tr][td] [/td][td]
[/td][td]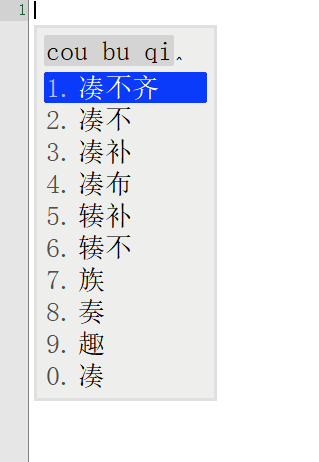 [/td][/tr]
[/td][/tr]
[tr][td] [/td][td]
[/td][td]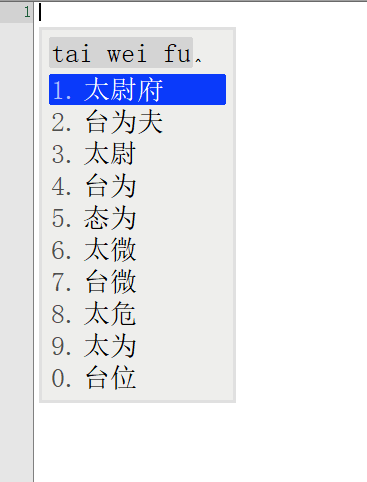 [/td][/tr]
[/td][/tr]
[tr][td]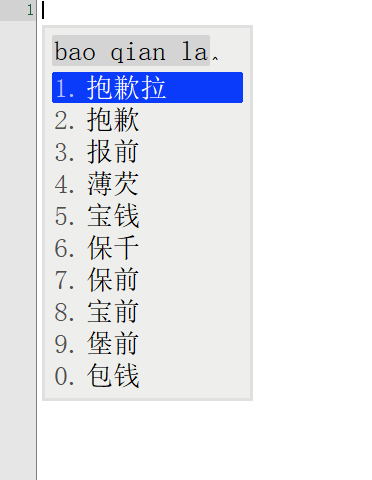 [/td][td]
[/td][td] [/td][/tr]
[/td][/tr]
[tr][td] [/td][td]
[/td][td]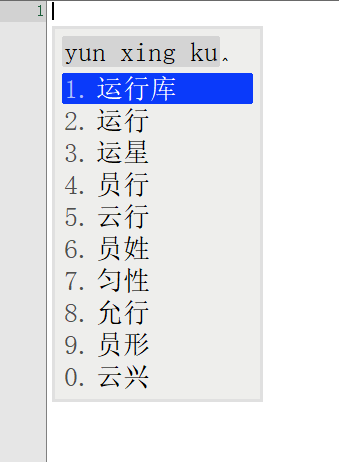 [/td][/tr]
[/td][/tr]
[/table][/align]
对比前后输入结果发现,词库容量涨到4倍之后,准确率大大增加。
长尾效应,用来描述诸如亚马逊公司、Netflix和Real.com/Rhapsody之类的网站之商业和经济模式。是指那些原来不受到重视的销量小但种类多的产品或服务由于总量巨大,累积起来的总收益超过主流产品的现象。在互联网领域,长尾效应尤为显著。
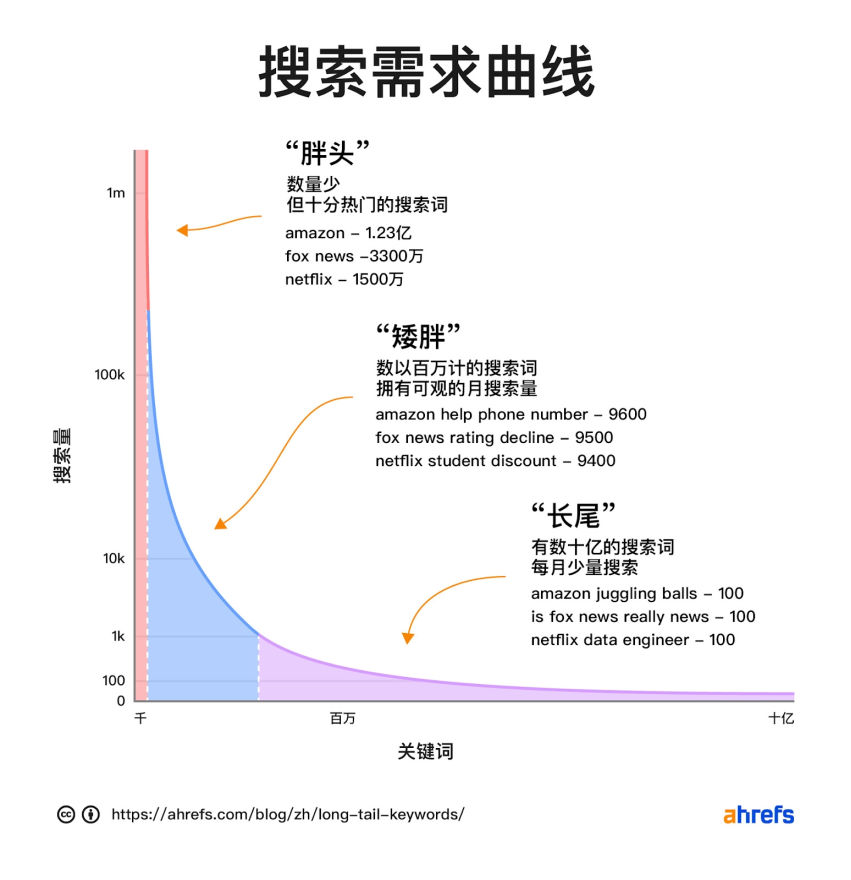
在语言分析这个领域,也存在长尾效应。没有绝对的核心词语、热门词语。
绝大多数词语都是相对冷门的词语,词语的绝大部分是由排名相对靠后的相对冷门词语组成的。
想做一个数据文件比较小并且覆盖词语比较全面的输入法,不太可能。 从信息熵的角度,数据无论如何优化压缩储存都是存在极限的,极限的大小与词语的数量和复杂度相关。
1050万词语增强包解压后有572MB,现在的储存设备比较廉价,使用更大的空间换来更高的输入准确率,普通人都是能够承受的。
下载链接:
https://hong-yan.lanzouw.com/b00vvkivc 密码:1234
输入法的发布得到不少网友的热情反馈。有的表示感谢和赞赏,有的提供建议,还有不少问题反馈的。
这里统一回复以下:
1.要求五笔最多4个字符
这是目前用户反应最多的问题,不能适应这种类似五笔单字模式的新型五笔输入模式,类似极点五笔那种 p12+p22,p11+p21+p31+p32,p11+p21+p31+p41
计算四码最大容量,也就是26个拉丁字母组成的4码表所有可能的排列组合,26^4 约等于45.7万,本输入法词汇量是230万,增强包有1050万,绝大部分是 2-4个字的词语,不管如何优化,重码率仍然很高。 如果有需要,可以把极点五笔的五笔词语码表导入到你喜欢的输入法平台,比如多多输入法、rime输入法、冰凌输入法、精灵五笔等等平台。这样做到小而美,可以对常用词组做到肌肉记忆,在某些特定的领域做到高速输入,码长和效率兼顾。
鸿雁输入法无法按照极点五笔那种方式对2-3个字的五笔进行编码,因为这样的话,重码率太高,如果使用词语为单元进行输入的时候,出现大量的重码,会影响输入体验,还不如使用单字输入模式。
2.输入法不能正常运行
安装“Visual C++ Redistributable Packages for Visual Studio 2015, 2017 and 2019.exe”,重启系统。 目前win11 系统不兼容,可能是系统输入法相关的api有变动。目前测试正常运行的有win7 32bit、win7 64bit、win 10 64bit。
3.词库同一个词语中存在正确的词语拼音也存在错误拼音,没有筛选。
鸿雁输入法自带的单字拼音库,是目前网上能找到的最准确的拼音库。
拼音数据以新华字典、通用规范汉字字典、异体字字典为准,作为第一阶梯数据。使用汉典网、百度汉语、字统网的数据作为补充,作为第二阶梯数据。 unicode 13标准中的汉字拼音、字海(叶典)网的拼音数据存在不少错误,辞源、古汉语常用字字典第5版、汉语大词典、汉语大字典、现代汉语词典第7版的拼音数据因为数据来源是通过OCR获得的,也存在不少错误。这些数据仅用于第三梯队,不直接采纳数据,仅仅对第一、第二阶梯的拼音数据投票。
如果有疑问,可以查看上面提到的字典、词典看看有没有这个读音。
因为校核词语拼音库需要大量时间,作者目前缺乏人力完成这样的工作,只能暴力穷举,这是没有办法中的办法。只要保证正确的拼音出现,保留废词的空间换来正确的拼音一定出现,这个代价是可以承受的。
rime输入法linux平台安装手记
================================================================================
linux mint
================================================================================
sudo apt-get install build-essential cmake doxygen ibus-rime libboost-all-dev libgoogle-glog-dev libgtest-dev libibus-1.0-dev libleveldb-dev libnotify-dev libopencc-dev librime1 librime-dev libz-dev
ibus-daemon -drx
/usr/share/rime-data
/home/user/.config/ibus/rime/build
================================================================================
deepin linux
================================================================================
sudo apt-get install build-essential capnproto cmake doxygen fcitx-rime fcitx-rime-dbgsym g++-multilib gcc-multilib git ibus-rime libboost-all-dev libgoogle-glog-dev libgtest-dev libibus-1.0-dev libleveldb-dev libmarisa0 libmarisa-dev libnotify-dev libopencc-dev librime librime1 librime-bin librime-data librime-data-array30 librime-data-bopomofo librime-data-cangjie5 librime-data-combo-pinyin librime-data-double-pinyin librime-data-emoji librime-data-ipa-xsampa librime-data-jyutping librime-data-luna-pinyin librime-data-pinyin-simp librime-data-quick5 librime-data-sampheng librime-data-scj6 librime-data-soutzoe librime-data-stenotype librime-data-stroke librime-data-terra-pinyin librime-data-wubi librime-data-wugniu librime-data-zyenpheng librime-dev libssl-dev libyaml-cpp0.6 libyaml-cpp-dev libz-dev marisa valgrind zlib1g-dev
cd ~
git clone -b v0.10.2 https://github.com/capnproto/capnproto.git
git clone -b 1.5.0 https://github.com/rime/ibus-rime.git
cd ~/capnproto/c++
autoreconf -i
./configure
make -j6 check
sudo make install
cd ~/ibus-rime/librime
cd librime
make
sudo make install
cd ..
make
sudo make install
ibus-daemon -drx
fcitx -d
/usr/share/rime-data
/home/user/.config/ibus/rime/build
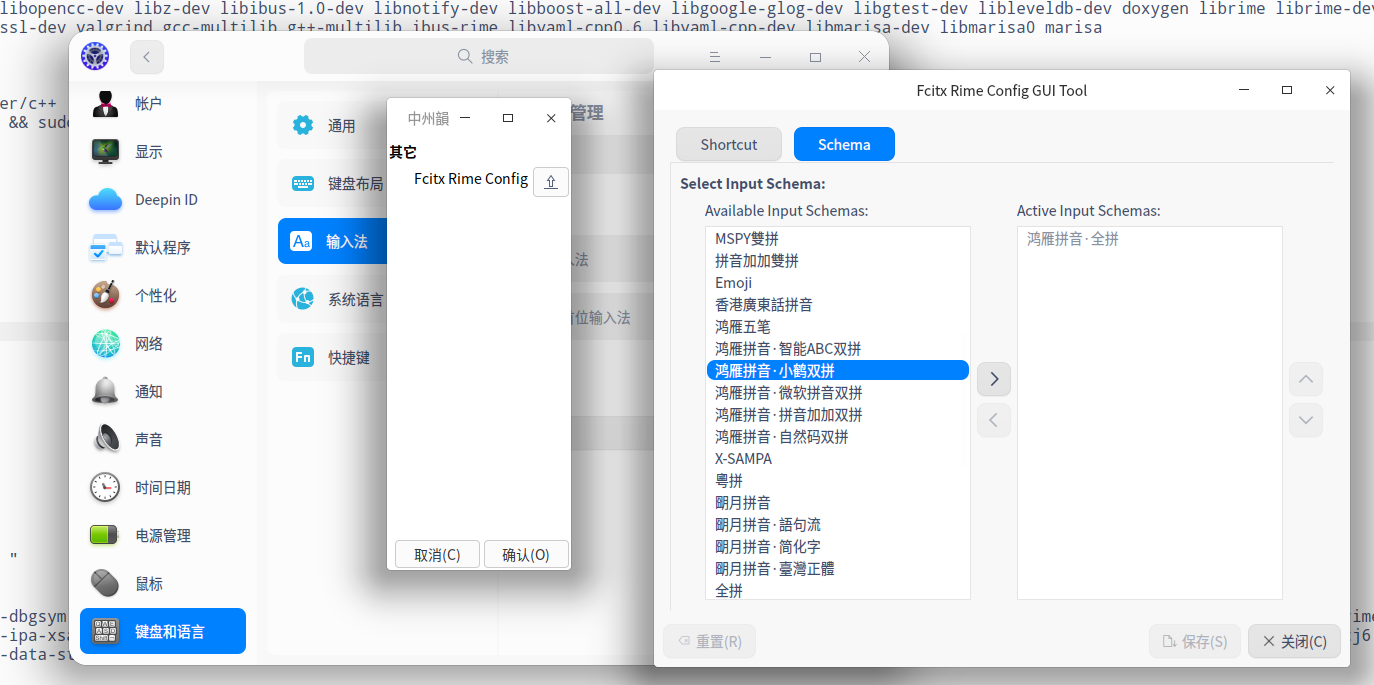
/usr/lib/x86_64-linux-gnu/fcitx/libexec/fcitx-qt5-gui-wrapper rime/config
================================================================================
ubuntu
================================================================================
sudo apt-get install build-essential capnproto cmake doxygen fcitx5 fcitx5-rime g++-multilib gcc-multilib git ibus-rime libboost-all-dev libgoogle-glog-dev libgtest-dev libibus-1.0-dev libleveldb-dev libmarisa0 libmarisa-dev libnotify-dev libopencc-dev librime1 librime-bin librime-data librime-data-emoji librime-data-jyutping librime-data-scj6 librime-data-soutzoe librime-data-stenotype librime-dev librime-plugin-charcode librime-plugin-lua librime-plugin-octagram libssl-dev libyaml-cpp0.7 libyaml-cpp-dev marisa rime-data-array30 rime-data-bopomofo rime-data-cangjie5 rime-data-combo-pinyin rime-data-double-pinyin rime-data-ipa-xsampa rime-data-ipa-yunlong rime-data-luna-pinyin rime-data-pinyin-simp rime-data-quick5 rime-data-sampheng rime-data-stroke rime-data-terra-pinyin rime-data-wubi rime-data-wugniu rime-data-zyenpheng valgrind zlib1g zlib1g-dev
cd ~
git clone -b v0.10.2 https://github.com/capnproto/capnproto.git
git clone -b 1.5.0 https://github.com/rime/ibus-rime.git
cd ~/capnproto/c++
autoreconf -i
./configure
make -j6 check
sudo make install
cd ~/ibus-rime/librime
cd librime
make
sudo make install
cd ..
make
sudo make install
ibus-daemon -drx
fcitx5 -d
sudo nautilus
/usr/share/rime-data
/home/user/.config/ibus/rime/build
================================================================================deepin linux平台截图
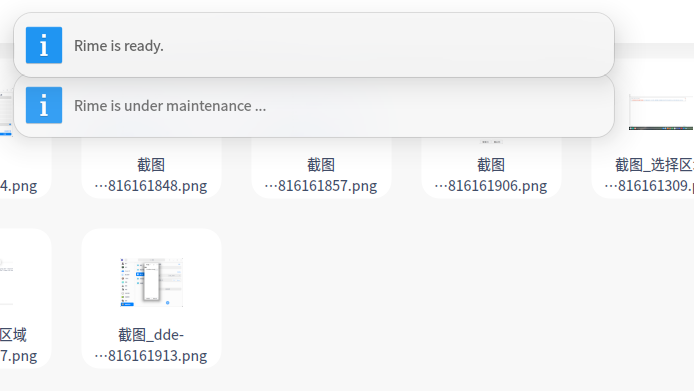
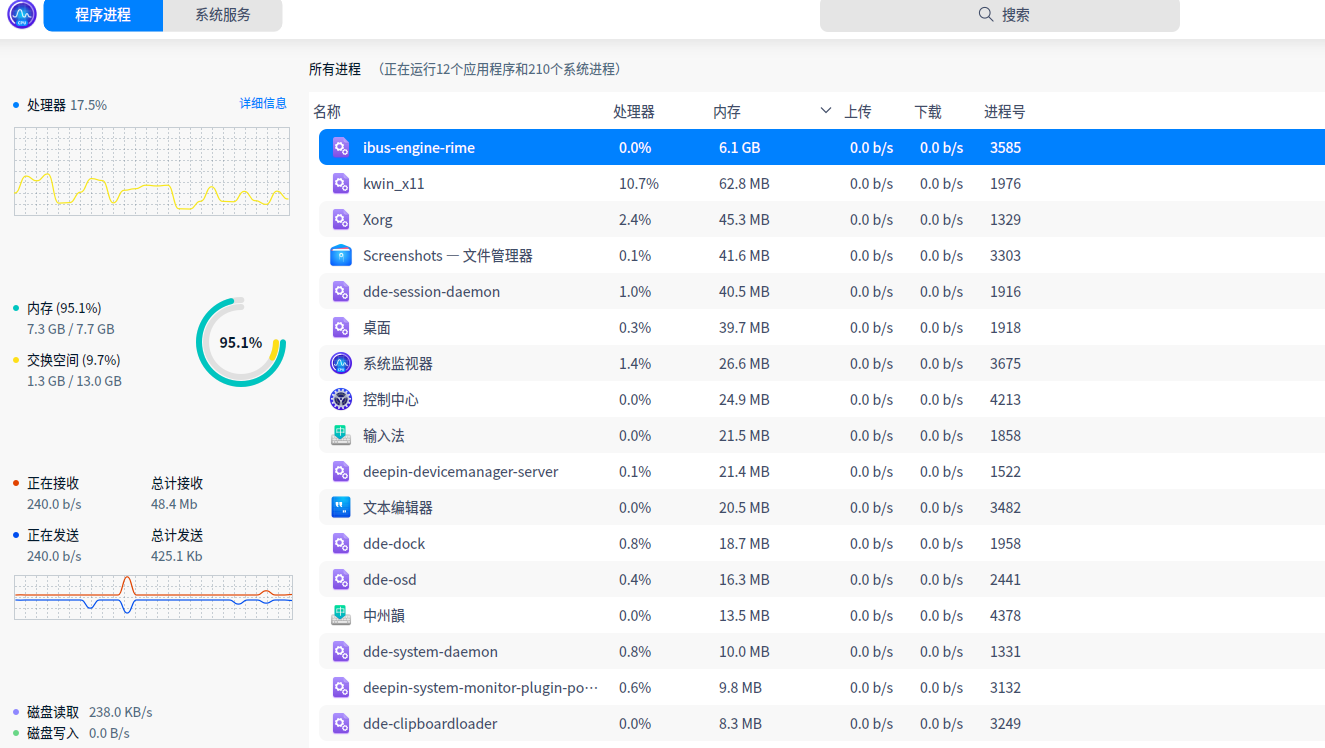

ubuntu平台截图
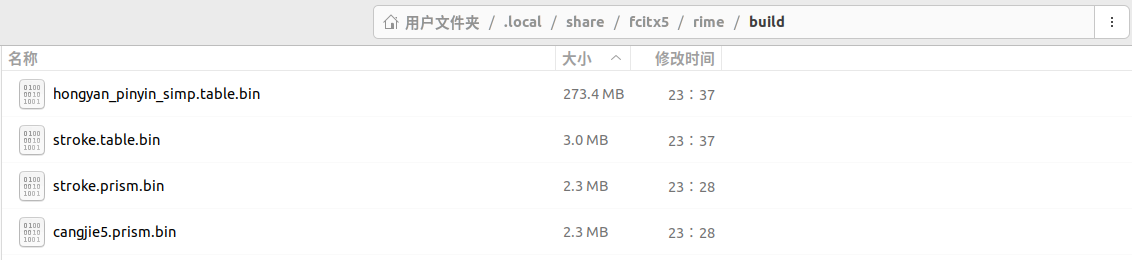

离线
页次: 1